If you work in digital marketing, chances are you’ve come across the term “data clean room” in the past couple years. However, I’ve found it to be one of the least understood topics among folks in the industry. This is unfortunate, as I believe data clean rooms (and data collaboration more broadly) will be a foundational technology in the modern, 1st party data (1PD) driven landscape.
As with many concepts in mar/adtech, understanding how the technology works, why it’s important, and how to contextualise its role within an already confusing landscape can be difficult. To help, I’ve written this guide covering what I believe to be the essential concepts, all in one place.
Here you’ll learn what data clean rooms (or DCRs for short) are, how they work, what data matching looks like inside a DCR, how to conceptualise use cases, what makes a data clean room “clean”, different DCR categories, and a few other tidbits. To help illustrate these concepts, we’ll also lean heavily on visuals and diagrams.
Note that this guide isn’t 100% exhaustive and there are certainly nuances that I don’t cover given how rapidly the space is evolving. However, I believe that by the end, you’ll know more about DCRs than 95% of your peers. Not only that, you’ll have a stronger conceptual chassis on top of which more knowledge can be added.
To skip directly to a specific section, please use the following links:
Estimated reading time: 24 minutes
Ready? Great, let’s begin.
What are Data Clean Rooms?
Ok, let’s not bury the lead. So what are Data Clean Rooms?
Data Clean Rooms are secure environments where two (or more) parties can upload their user data to collaborate on mutually agreed upon use cases without actually sharing the data or compromising the privacy of their users.
Why have they become a thing?
A confluence of factors have contributed to the rise of data clean rooms (and data collaboration more generally). Some of the more prominent include the following:
Data privacy regulation + user concerns – With the introduction of legislation like GDPR (EU) and CCPA (CA) as well as general societal concerns, attention on data privacy has never been higher. Clean rooms offer a path for the industry to respect said data privacy while still allowing for marketing use cases.
Decline of traditional 3P identifiers – The continued decline of 3P identifiers like cookies (yes even if Chrome doesn’t deprecate them as planned) and IDFA breaks much of the connective tissue used for targeting and measurement in adtech. This has created a vacuum for technologies that can support data-driven use cases through alternative means.
Increased media + data fragmentation – The walls between media owners (e.g. walled gardens, ad networks, large publishers) have never been higher. This is due in large part to scaled media owners building up their 1PD stores given the relative increase in value due to the aforementioned decline of cross-site identifiers. As a result, the landscape has never been more fragmented in terms of both media and data access across different parts of the internet.
Increased demand for 1P data collaboration – With 3P cross-site identifiers becoming decreasingly viable, the importance of 1PD continues to rise across the industry. As companies look to increase the practical value of their first party data, the appetite for collaboration between different parties also increases. DCRs enable these collaborations by allowing parties to do so safely in a secure environment that preserves user privacy.
Technological advancements – Improvements in cloud computing, data security, and encryption technologies have made it feasible to build and operate data clean rooms that can process large datasets efficiently while ensuring data privacy and security.
How Data Clean Rooms work (on a high level)
What we’ll do next is walk through how DCRs work on a very high level, then dive deeper into specific DCR elements and concepts to further build and reinforce understanding.
Setup
A DCR setup begins when multiple* parties agree to partner for data collaboration. Said parties can include brands, agencies acting on behalf of brands, media companies, walled gardens, data companies, pretty much any entity with scaled 1PD. One party instantiates (sets up) a Data Clean room instance (Figure A). The word instance is important because a DCR isn’t a single database that gets reused by different parties. Generally speaking, a new DCR instance is created for each set of collaborators. Note that a DCR can involve more than two parties, but to keep things straightforward, we’ll stick to 2 parties for the examples in this presentation.
*Note that a DCR can involve more than two collaborating parties, but to keep things straightforward, we’ll stick to two parties in our examples.

Figure A – Abstracted DCR setup
Data upload and ingestion
Collaborating parties then upload their datasets into the DCR (Figure B). This can include different types of data including email addresses, device IDs, or other 1P identifiers, and can come from wherever that data is stored (e.g. CRM, Cloud Data Warehouse, CDP). At this stage, the data is often anonymised or pseudonymised to protect individual identities. For example, email addresses can be hashed to obscure the original information while maintaining the ability to match records across datasets.
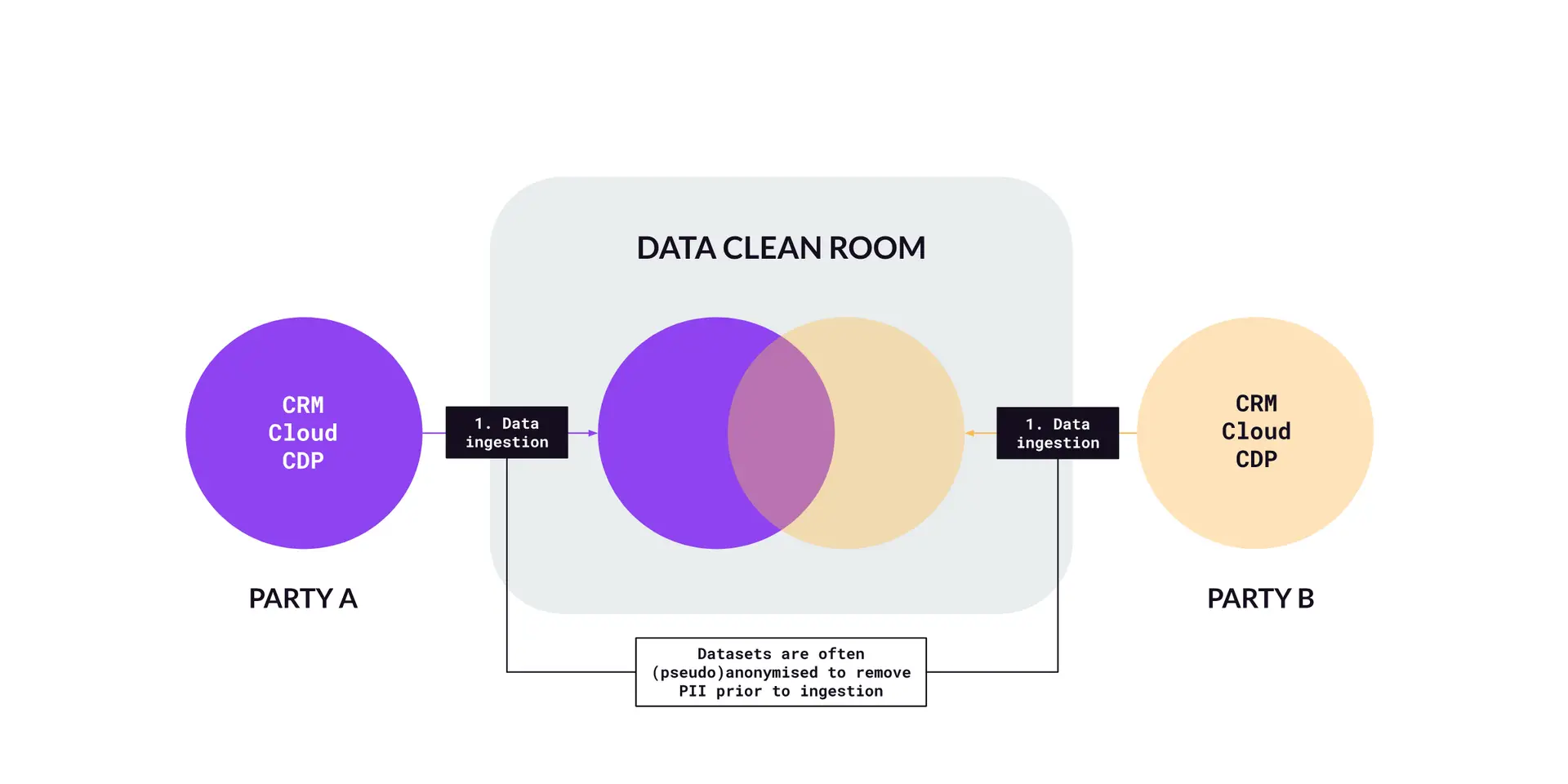
Figure B – Data upload and ingestion
Data processing and matching
Once the data is ingested, the clean room software processes it to enable matching and analysis (Figure C). This involves aligning datasets from different sources based on shared identifiers. Before the actual matching of data, privacy enhancing technologies (or PETs, which we’ll discuss more later on) are applied to ensure that the data remains private during the matching process. To match data sets between the two parties, a common identifier is required. Identifiers accepted by DCR can vary, but examples can include hashed PII like email address, or universal IDs such as UID2 or RampID. Regardless of which option is chosen, PETs are used to ensure that the underlying data remains hidden and can’t be reverse engineered. This protected output (and not the ingested raw data) is what’s used to match data sets.
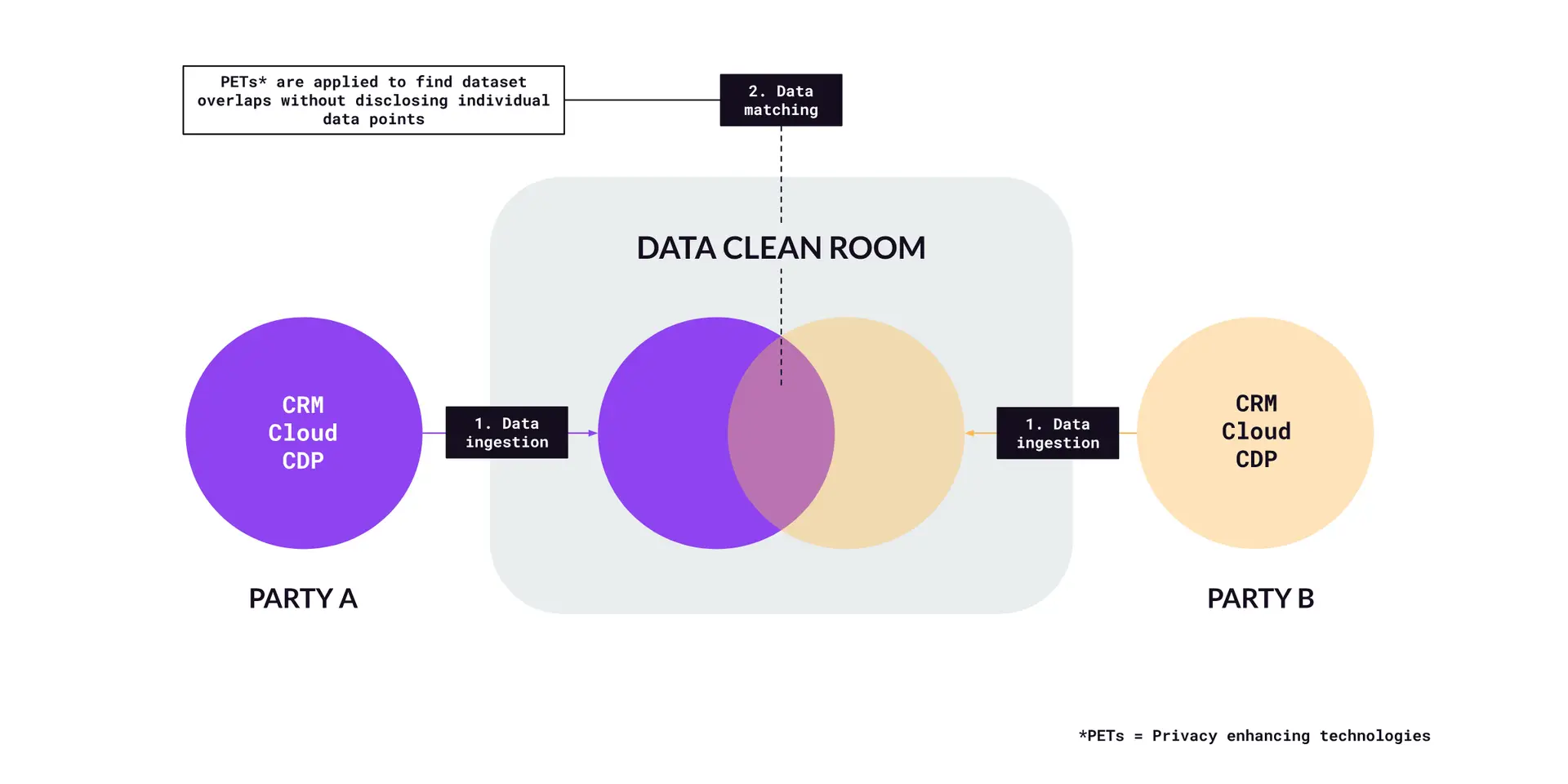
Figure C – Data processing and matching
Data collaboration (which refers to whatever the agreed upon use case is)
After matching, the DCR enables various analyses and use cases from the combined datasets (Figure D). This can range from simple aggregations (e.g., counting the number of matched records) to more complex analytics (e.g., behavioral segmentation or purchase intent analysis). The results are aggregated to varying levels, meaning that individual user information is not revealed. Differential privacy techniques (a specific PET) can be applied here to add noise to the data or query results, ensuring that the output doesn’t compromise individual privacy.
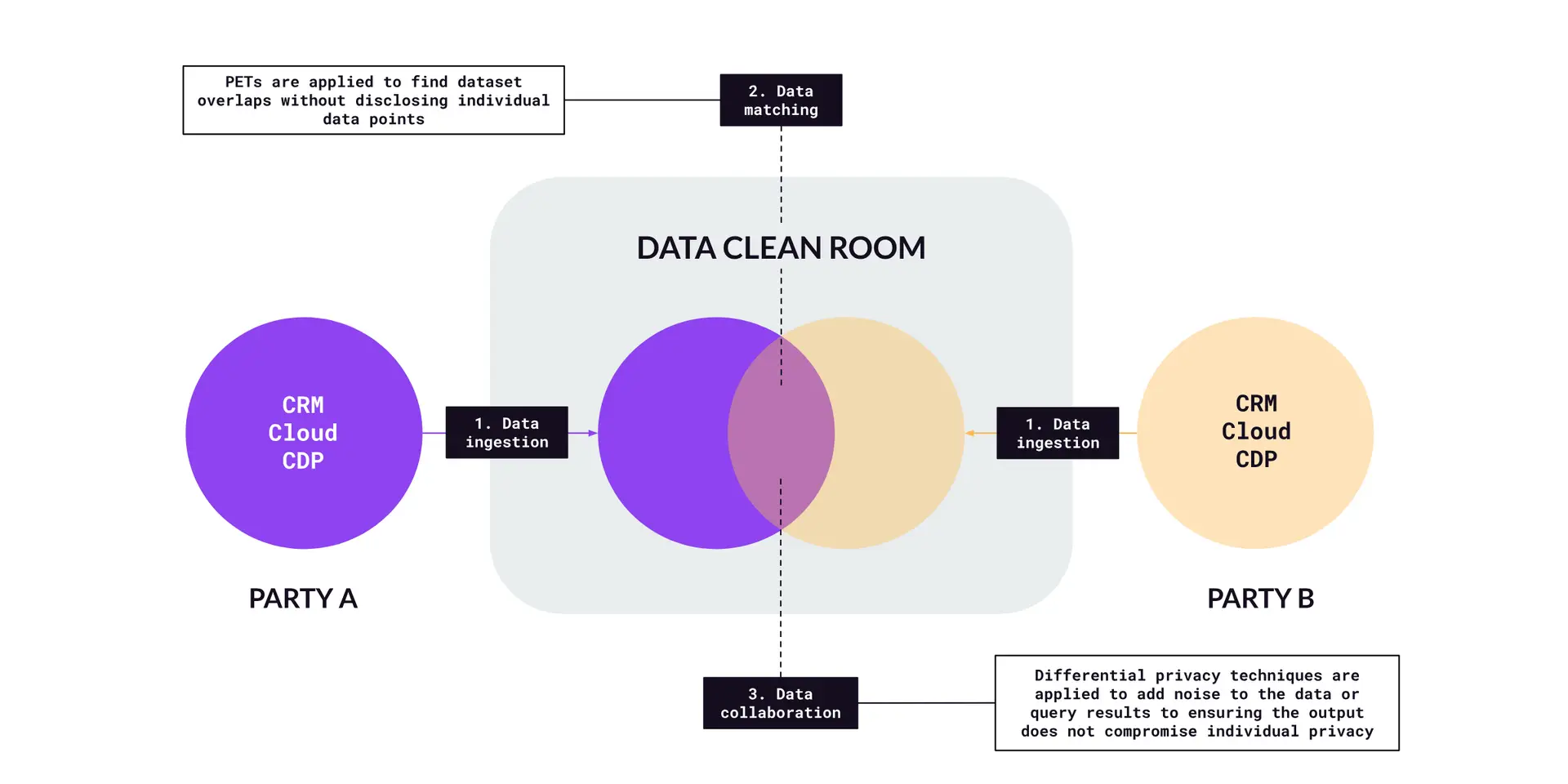
Figure D – Data collaboration
Output for marketing use cases
The final step involves outputting the processed and analysed data in a form that’s useful for marketing applications. This can include audience segments for targeted advertising, insights for visualisation, or matched data for running models. The key is that any data or insights extracted from the clean room are compliant with privacy regulations and don’t reveal any PII. Oftentimes, the aggregated outputs are syndicated (sent) to different platforms either via native or API integrations for different use cases. You can see several examples organised by use case category below (Figure E).

Figure E – Marketing output
A very important concept here is that the data output Party A sends for use are aggregations of their own data. Despite being a collaborator, data from Party B is not combined with that of Party A. Rather, Party A now has more insight into what segments of their own data can be used for their desired use case(s). This might sound counterintuitive, but don’t worry, we’ll cover this in more detail later.
What data matching looks like in a Data Clean Room
Let’s say that the venn diagram intersection area (Figure F) is where the matching takes place. To make this a bit more real, let’s replace Party A with a FMCG brand and Party B with a Streaming Service (like Disney+, since they actually have their own DCR platform).
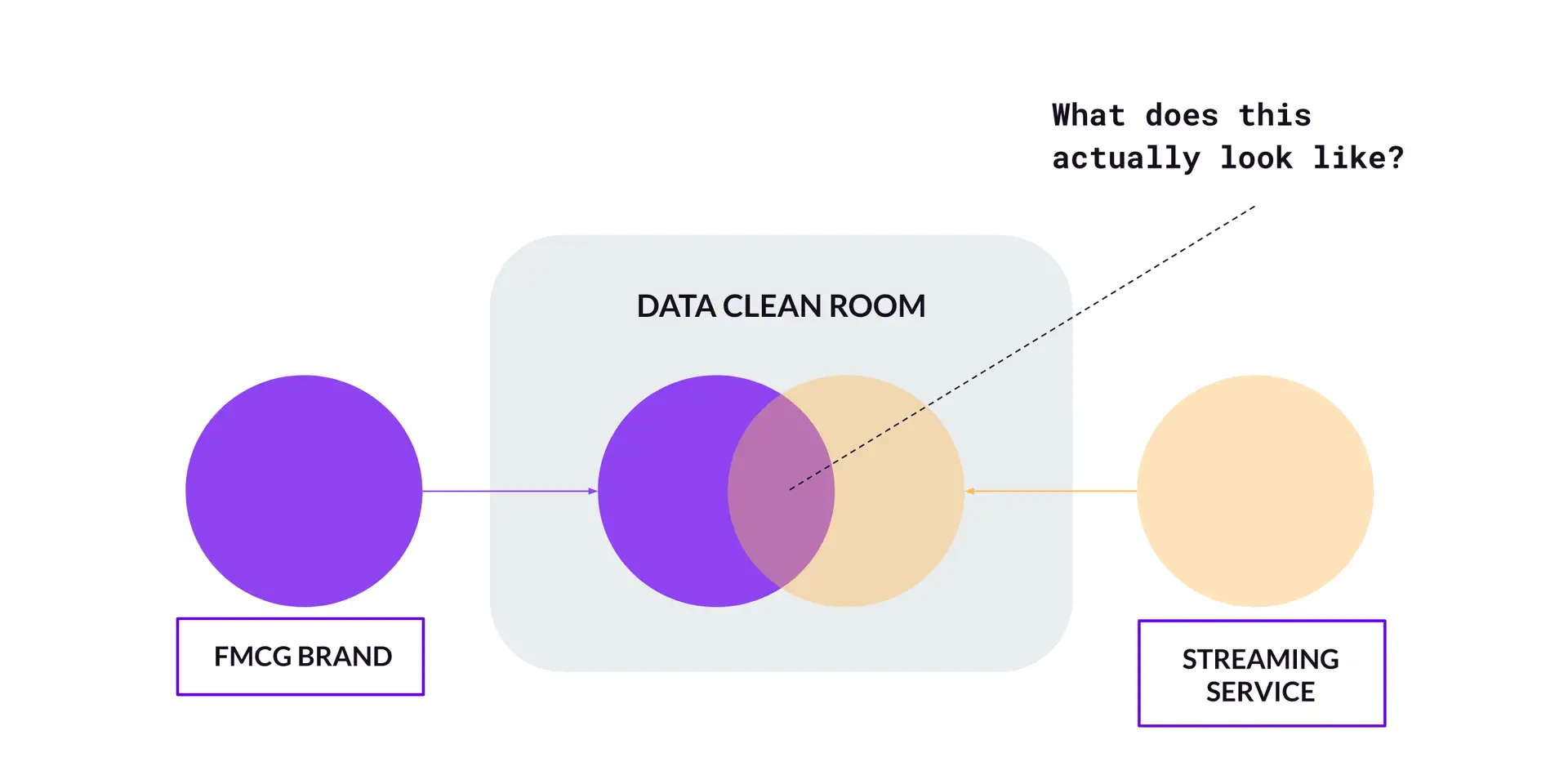
Figure F – Data matching pt.1
Now, let’s say that the FMCG brand and Streaming service have agreed to run an overlap analysis with the goal being for the FMCG brand to be better able to target their audience segments against the Streaming services’ programming.
The dataset for the FMCG Brand includes encrypted customer IDs, the customer’s age group, and the food cohort they belong in (this segmentation would have been done ahead of time). On the other side, the streaming service’s dataset also includes encrypted user IDs (resolved to the same format as that of the FMCG Brand), the user’s primary device, and the programming genre they belong to (Figure G).
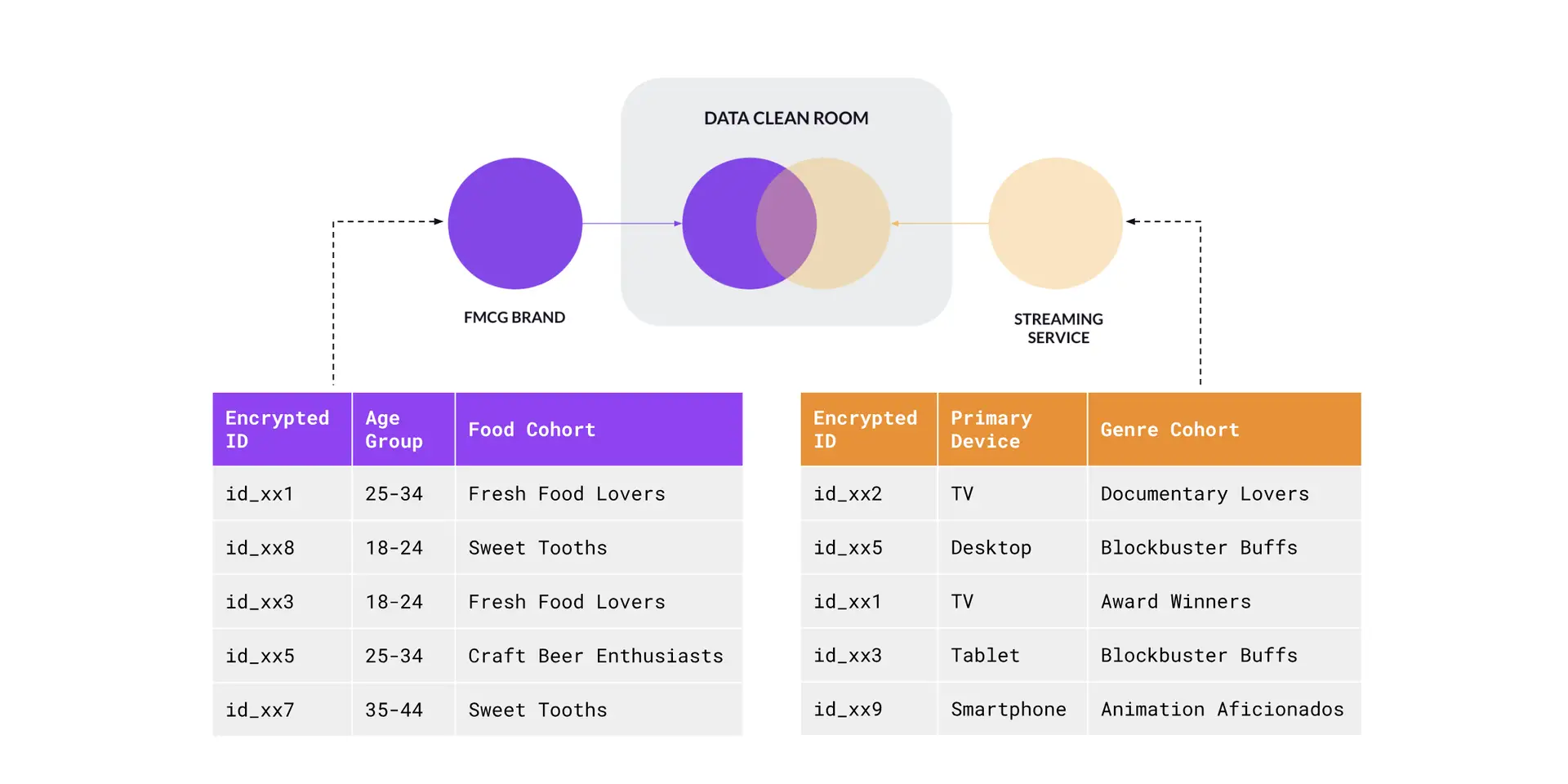
Figure G – Data matching pt.2
The matching uses the encrypted ID as the join key with the output being a new table containing the number of customers belonging to different food and genre cohort combinations. As we can see (Figure H), while individual users are included in the ingested data, only aggregated data comes out. And to ensure data privacy and that we can’t identify individual users, rows containing fewer than 50 users are redacted and not included in the output.

Figure H – Data matching pt.3
While INNER JOIN queries (ie. the venn diagram overlap area) are the most common DCR matching function, other queries are also used depending on use case and what’s permitted to ensure collaboration is done in a privacy-preserving manner. And what’s permitted can be based on the DCR provider, user configurations when setting up the DCR, and/or the dataset itself.
Conceptualising Data Clean Room use cases
This part’s important. Hell, this might be the most important part of this entire write-up.
Data Clean Rooms allow one party to use another party's (or parties') data to reveal new data points about their own users.
All use cases are ultimately unlocked by this concept.
In other words, in a DCR collaboration, party A is not actually adding or activating another party B’s data. Party A is using party B’s data to reveal new insights about their own data. And with those insights, party A can unlock new use cases.
To illustrate, we’ll next go through some use case category examples. For our purposes, we’ll assume that a brand is the party that sets up the DCR instances in our examples. That said, most of these use cases can be with media owners/publishers initiating as well.
Audience addressability and activation

Figure I – Audience addressability and activation use cases
In this category (Figure I), the brand wants to discover existing or new audiences for media targeting and/or measurement at scale. The second party in the collaboration is a media owner or data provider. In these use cases, the brand would use the data provided by the media owner or data provider to reveal new attributes about their own users or customers. These attributes can then inform the downstream audiences use cases highlighted above.
Note that this can work both ways in that a media owner can use a DCR in a similar manner to better understand which audience segments on their properties drive more engagement to inform their ad products for prospective advertising clients.
Data enrichment and insight generation
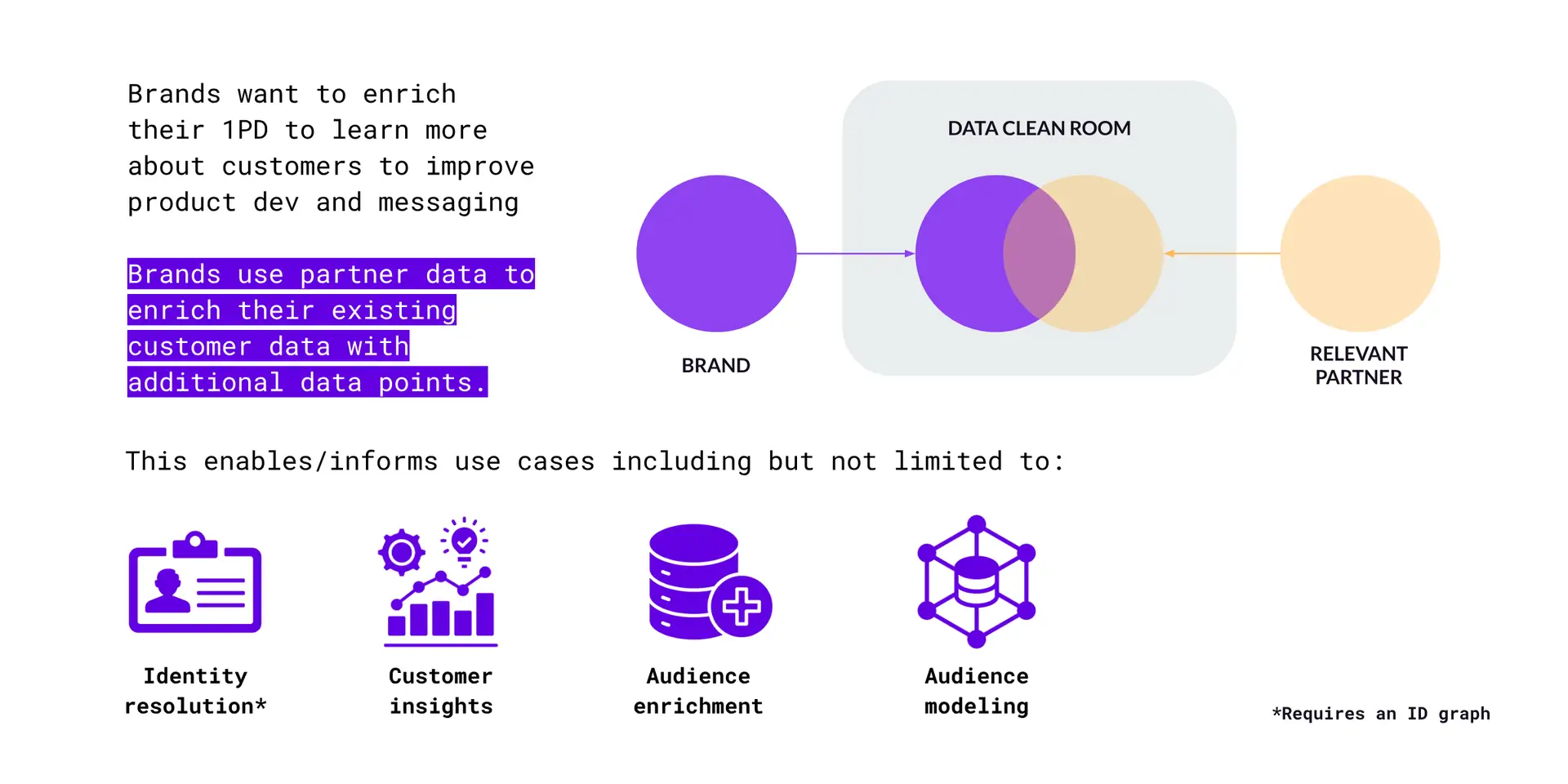
Figure J – Data enrichment and insight generation use cases
In this category (Figure J), the brand wants to enrich their existing 1PD to better understand customers to improve everything from product development to creative messaging and media planning. Here, the second party can be any entity with value-adding data. In these use cases, the brand uses partner data to enrich their existing customer data, revealing new attributes (demographic, psychographic, behavioral, etc.) to better understand their customers and optimise/inform the use cases highlighted above.
Note that use cases involving identity resolution (ie. the process of linking different data points to a unique individual) requires the use of one or more ID graphs, which DCRs typically have access to. We’ll cover the role of ID graphs in more detail shortly.
Attribution, Measurement, Optimisation
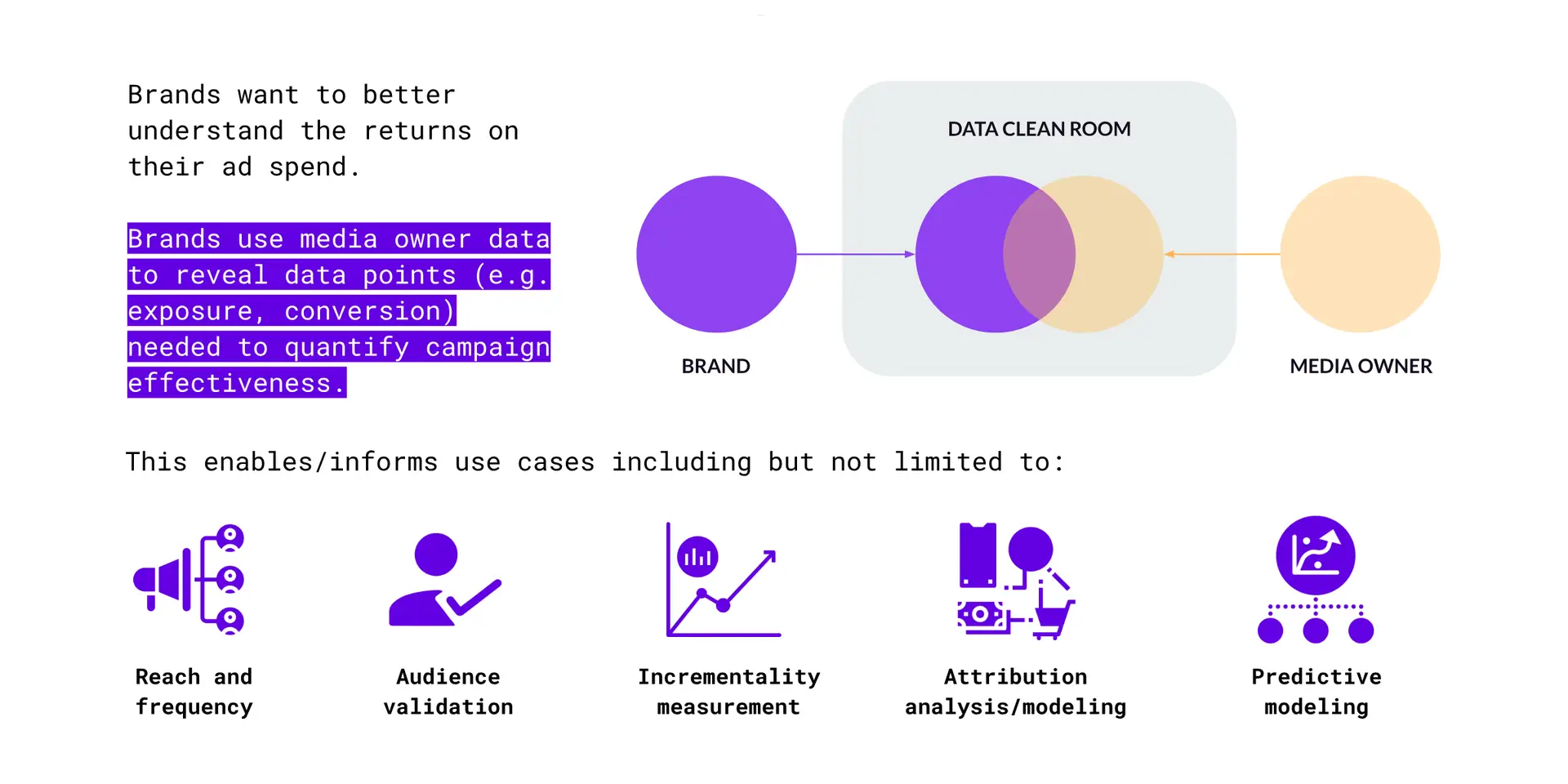
Figure K – Attribution, Measurement, Optimisation use cases
In these use cases (Figure K), the brand is looking to better understand the business impact and returns generated by their ad investment. Here, the brand would leverage media owner data to reveal data points (e.g., ad exposure, ad engagement, conversions, sales) required to better quantify the effectiveness of their marketing and advertising campaigns. This can then inform the listed downstream use cases.
The role of Identity Graphs in Data Clean Rooms
The main purpose of identity graphs (or ID graphs) in DCRs is to improve match rates between datasets from different parties. Why is this important? Well DCRs work by joining different datasets, typically using some sort of user ID as the common field. Beyond scenarios where datasets already share the same identifier, the ability to join datasets will depend on an ID graph(s). This is crucial for data collaboration, as match rates often dictate the scale and effectiveness of use cases.
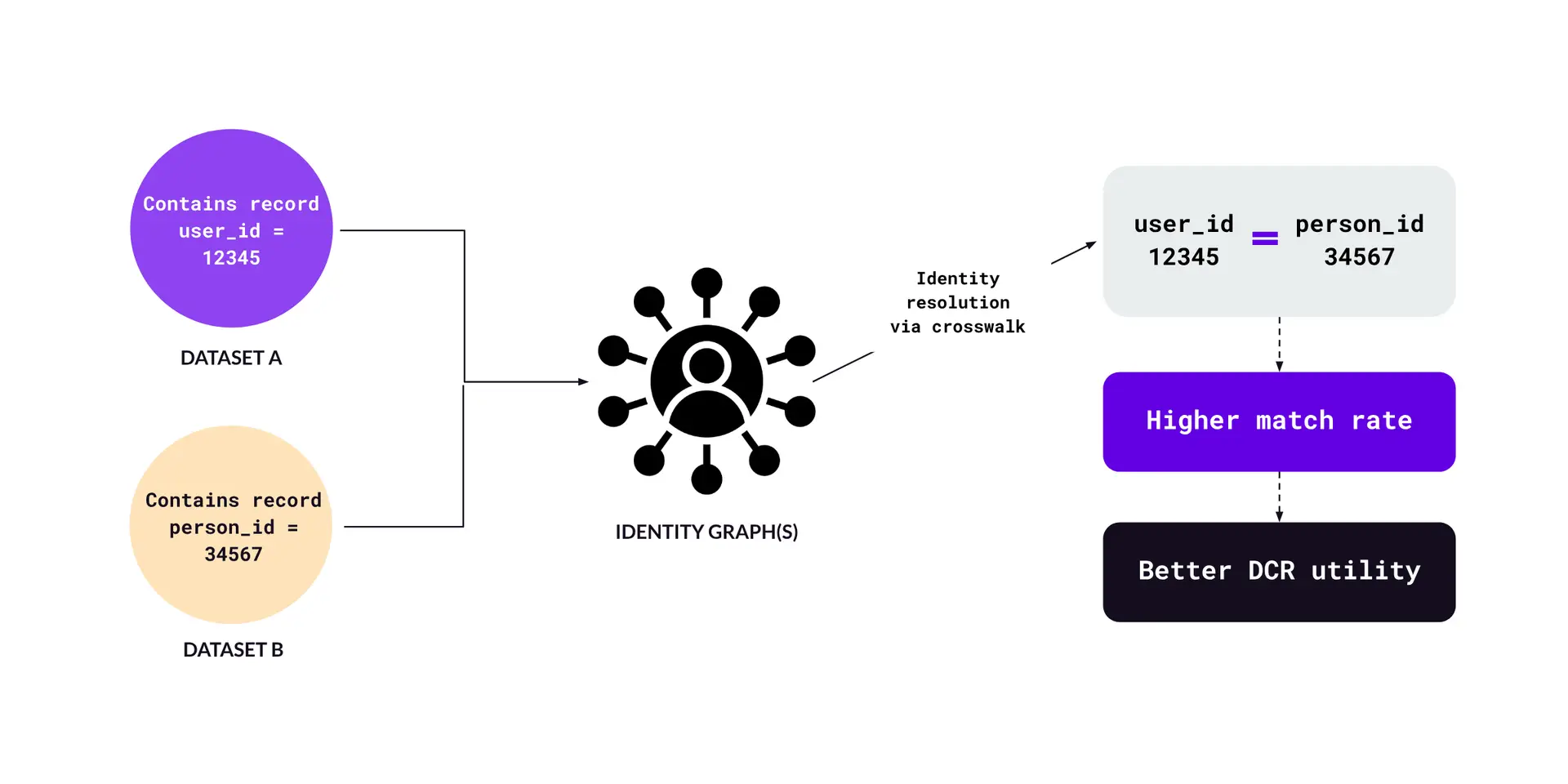
Figure L – ID graphs in DCRs
For example (Figure L), let’s say that Dataset A contains a user record with “user_id” = 12345, and Dataset B contains a user record with “PersonID” = 34567. Through what’s called an ID graph crosswalk (ie. walking from one ID set to another), it’s determined that user_id: 12345 == PersonID: 34567. This indicates that the identity between those records has been “resolved.” This process results in a higher match rate, which leads to better DCR utility.
User data models in Data Clean Rooms
We lightly touched on this when going through the use case categories, but for more advanced use cases, data scientists can use models in DCRs in two ways: “Build” or “Import” (Figure M):

Figure M – Data models methodologies in DCRs
For “Build”, it’s worth keeping in mind that matched datasets can be used like any other dataset as long as the data doesn’t leave the DCR environment. The built model can then be deployed on existing customer data within the DCR instance where data scientists can analyse the results for different use cases. As with all use cases, insights are derived from the aggregated data, ensuring that no PII is exposed. The analysis can inform decision-making, enhance targeting strategies, and improve the effectiveness of marketing campaigns. Models that are imported can be used for similar use cases.
For “Import”, a party brings an existing, pre-trained model (ie. trained outside the DCR) into the DCR for use against the data contained within the DCR. The use cases that can then be enabled are potentially the same as that of models built within a DCR instance.
At this point, you might be wondering whether DCRs actually facilitate new use cases, or if they simply allow for existing data strategies to be executed in a more secure, privacy-compliant manner. The answer (as far as I can tell) is the latter. The use cases we outlined aren’t “new”, but DCRs provide users with access to 1P data sources with whom to collaborate that were previously (practically) impossible. This leads us to another key concept:
Most use cases enabled by DCRs aren’t new, but they provide users with access to 1P data sources with whom to collaborate that were previously (practically) impossible.
Bringing the "Clean" to Data Clean Rooms
We lightly mentioned these near the beginning, but Privacy Enhancing Technologies (or PETs) is what makes a Data Clean Room a Data Clean Room. Without them, a DCR would pretty much just be a high-powered data warehouse. DCRs employ a broad suite of PETs to ensure that data analysis and collaboration between parties occur in a secure and privacy-compliant manner. Below are some PETs that are commonly used in DCRs. Note that PETs aren’t exclusive to DCRs, as they’re used in many other technologies, both in ad/martech and beyond.
Data Anonymisation – Removes or alters personal identifiers so that data can’t be associated with an individual without additional information. Anonymisation ensures that the data used within DCRs cannot be used to re-identify individuals.
Data Pseudonymisation – Replaces private identifiers with fake identifiers or pseudonyms. Unlike anonymisation, pseudonymisation allows data to be matched or linked with other datasets using pseudonyms, facilitating analysis without exposing personal identities.
Differential Privacy – Adds noise to the data or query results to prevent identification of individuals from the dataset. Note that this is the primary PET that accounts for data aggregation in DCRs, as it’s particularly useful in scenarios where statistical information needs to be shared without compromising individual data points.
Homomorphic Encryption – This technique allows computations to be performed on encrypted data without it needing to be decrypted first. The results of such computations are encrypted and can be decrypted only by the data owner. This allows complex data processing within DCRs while ensuring the underlying data remains secure
Secure Multi-Party Computation (SMPC) – Allows parties to jointly compute a function over their inputs while keeping those inputs private. In the context of DCRs, this allows multiple parties to contribute data to a shared analysis or model without revealing their individual datasets to one another.
Zero-Knowledge Proofs – A cryptographic method that allows one party to prove to another that a statement is true without additional info apart from the fact that the statement is true. In DCRs, zero-knowledge proofs can be used to verify the accuracy of data or computations without exposing the underlying data.
Again, this is just a high level sampling of some of the more common PETs you might come across in the context of DCRs. The objective here is to illustrate that there are a wide range of techniques and technologies that help protect data security and privacy while still enabling new insights to be derived and actions to be taken based on the data.
Applications of PETs can be calibrated (to a degree)

Figure N – PET calibration examples
The party that configures the DCR instance can generally calibrate the degree and application of PETs. Referring to Figure N, you can see that in the AWS DCR, aggregation minimums can be set at different levels, and in the Habu (on Snowflake) DCR, the user can adjust the Data Decibel (injection of random noise) and Crowd Size (minimum threshold to return data).
That said, the flexibility to adjust the level of PETs is subject to regulatory, technical, and contractual constraints. As such, collaboration between users, DCR providers, and legal advisors is key to finding the optimal balance between privacy protection and data utility.
Data Clean Room categories
DCRs come in different flavors. Figure O represents a few providers organised by category. Note that these categories aren’t absolute or exhaustive (some providers have evolved to be in multiple categories, and what I’ve included are just a few of the more prominent examples.

Figure O – DCR provider examples by category
Pure Play
These are provided by companies primarily specialising in DCR solutions with interoperability, flexibility and neutrality being defining features (ie. can work across all major clouds). They also include complementary features such as ID resolution, access to data marketplaces, and native s2s integration with mar/adtech systems. All this extends functionality and makes these providers more of a full-fledged data management solution.
They’re ideal for clients seeking self-serve options where they control the DCR settings without being tied to any one ID type or technology choice.
Data Platforms
These are DCRs provided by data platforms like Snowflake and Databricks. As a reminder, these are platforms that specialise in specific data workloads* such as data warehousing, big data processing and analytics. They’re designed to be interoperable across different clouds, allowing them to integrate with and operate on top of infrastructure provided by AWS, GCP, and Azure. There are however, some limitations relative to pure-play providers. For example, Snowflake DCR instances require all parties to be on Snowflake.
The other difference is that DCRs are just one of many data workloads provided by these platforms whereas pure-play providers focus on DCRs as the central offering. They’re also more suited for technical users whereas pure-play DCRs are more user-friendly with no or low-code UIs. This makes sense as Data Platforms are focused on providing a comprehensive platform that caters to data engineers, scientists, and analysts, with DCRs being one of many features available.
DCRs provided by these platforms would be most beneficial for clients already using them for their data needs, thus offering deep integration with existing features.
*Data workload = A program or application using computing resources to accomplish tasks
Media
These are DCRs provided by media companies. These can include both DCRs from media walled gardens like Google and Amazon, as well as those from publishers like Disney or NBCU. Unlike pure play and data platform DCRs, these operate as closed and centralised ecosystems where one of the participating parties will always be the DCR provider itself (e.g., Google Advertising, Amazon Ads)*. Use cases here are for advertisers who want to analyse and/or activate data within the specific media ecosystem in which they’re running ads.
Non-walled garden media owners can build their own DCR platform containing their data spine on top of other clean room infrastructure. These DCRs are interoperable in the sense that they can work on different clouds, but closed in that they only support use cases using ads data from their own properties.
Hybrid
This category represents DCRs from providers who combine elements from different categories. Companies like LiveRamp (who recently acquired Habu) and AppsFlyer fall into this category, blending characteristics of pure-play DCRs with specialised features from other categories. For example, Habu/LiveRamp can offer the interoperability of pure-play DCRs along with native identity resolution capabilities. AppsFlyer can also offer a DCR solution that can work across different cloud environments while also leveraging its core strength in mobile attribution, providing insights into app-based advertising performance (similar to media DCRs).
Hybrid DCRs are well-suited for organisations that require both the specialized features of data platform or media DCRs and the flexibility of pure-play solutions. For instance, a company using AppsFlyer could benefit from its mobile attribution expertise while also leveraging its DCR capabilities for broader data collaboration. Similarly, Habu/LiveRamp clients can enjoy the benefits of advanced identity resolution alongside flexible data collaboration features.
It should be mentioned that these days, public cloud providers also offer DCR services as part of their broader cloud services (Figure P). Obviously they’re designed to live within and synergise with said cloud services and are targeted toward existing users of their platforms.

Figure P – Marketing output
This can all be a bit confusing, but the take home message is that there’s a DCR type and flavor for just about every type of user and organisation. It really just shows how big of a thing data collaboration has become these days.
Data Clean Rooms can be centralised or decentralised
DCRs can also be centralised or decentralised. The former is relatively straightforward, the latter less so. Let’s spend some time here.
In this context, decentralised (or sometimes referred to as distributed) doesn’t mean a single DCR instance is split apart on different devices, servers, or anything like that. Instead what it refers to is the fact that the DCR cognition is decentralised and moves between multiple DCR instances (each owned by a partner within a single data collaboration). This would be what I call a “multi-DCR model”. Cognition here refers to the mechanisms that allow for data processing, matching, PETs, etc. As such, what makes for a DCR isn’t necessarily a single DCR instance, but rather the combined DCR instances of the parties that comprise a given DCR collaboration.
As mentioned, centralised DCRs are more straightforward, as it’s where cognition is centralised within a single DCR instance shared by the collaborators. Figure Q represents a model of a centralised DCR. Here, parties upload their data into a single, shared DCR instance. In other words, they bring their data to the cognition.
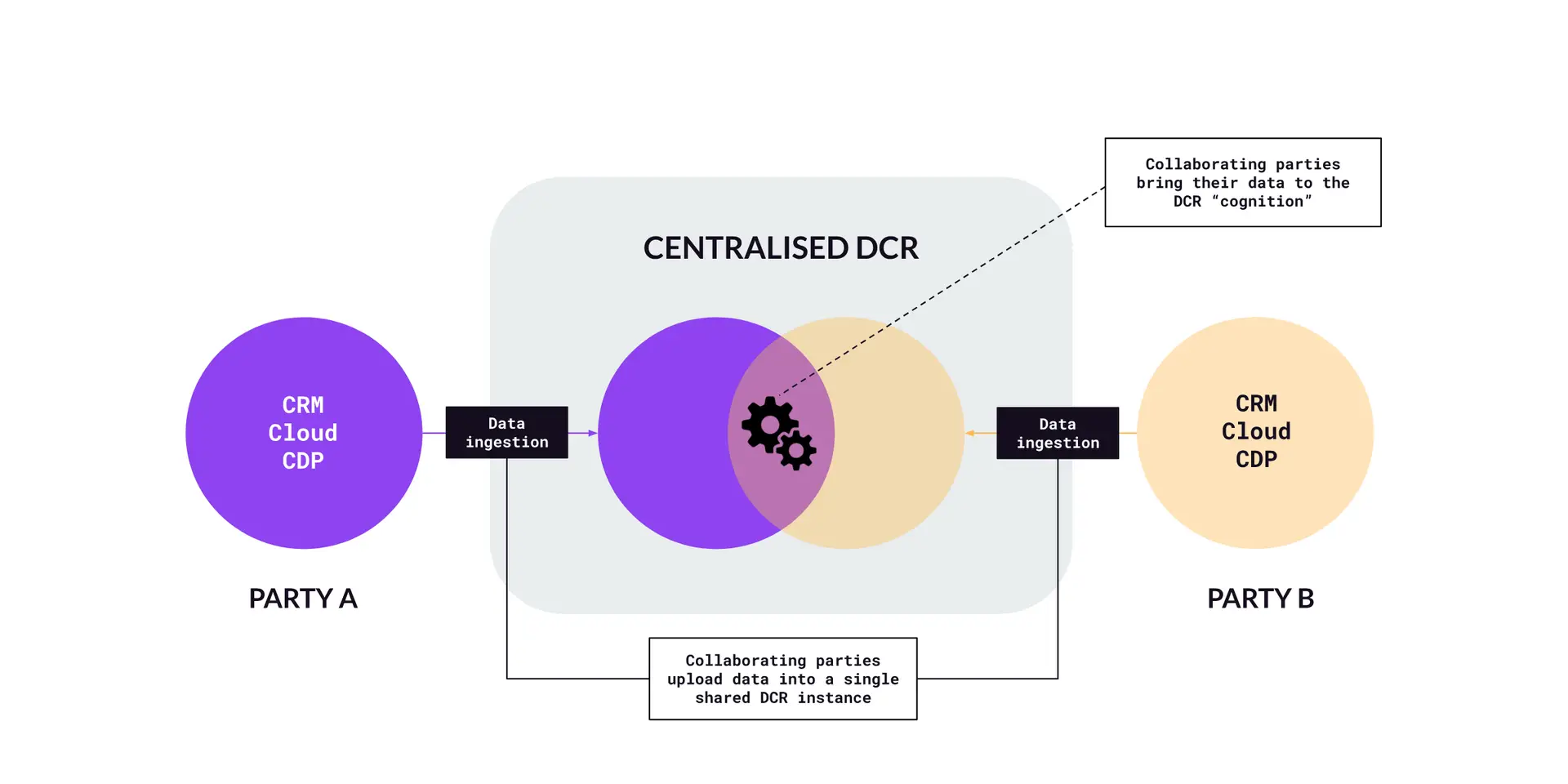
Figure Q – Centralised/Single DCR model
Figure R represents a decentralised DCR model. In this case, parties upload their data into their own DCR instance (ie. not shared). As such, another way to conceptualise this is as a multi-DCR model. The cognition goes to where the data sits (so the data itself doesn’t move). In other words, each partner keeps their data in their own DCR environment without the need to move said into the DCR environment of their collaborating partner.

Figure R – Decentralised/Multi-DCR model
Some of you may have heard some DCR providers saying how data doesn’t move in their product, thus making it more secure, etc. This refers to the decentralised model discussed above whereby a collaborating party’s data remains in their own DCR instance (thus not having to be moved to a shared DCR instance). This however, does not mean that said party doesn’t have to first upload their data into their own DCR instance. That still needs to happen.
Referring to Figure S below, in most instances, decentralised DCRs are associated with no or minimal data movement. On the other hand, centralised DCRs are typically associated with some degree of data movement (ie. users uploading their data into a shared DCR instance). That said, this doesn’t mean that all non-movement DCRs are decentralised or that DCRs with data movement are inherently centralised. There are exceptions, combined setups, and other nuances, so it’s not always an either/or thing.

Figure S – Data movement comparison
A few more things
New revenue source for media owners
Earlier I said that DCRs don’t necessarily enable “new” use cases, but grant organisations access to 1P data sources that was previously impossible. In addition, DCRs also provide a path towards a new revenue stream for media owners who possess scaled and differentiated 1PD. There’s been lots of discourse on the growing importance of 1PD in the data landscape, and how that could provide revenue to these types of publishers. The use of DCRs to grease the wheels on data collaboration use cases with brands is such an example (see Figure T for examples of media owners who have taken advantage).

Figure T – Marketing output
This path could be especially beneficial for non-walled garden media owners, as DCRs provide a way to unbundle data from media inventory that previously did not exist. The benefits also extend to advertisers, as they would now have the means to access media 1PD that would have been practically impossible in the past. , but non-game changing revenue source for walled gardens. In this way, some believe that DCRs will effectively replace DMPs and perhaps publisher CDPs over time for these use cases, which I agree with
Platform or Product?
Speaking of DCRs, DMPs, and CDPs, a question that’s sometimes asked is whether DCRs are a “platform” or a “product”. It’s a fair question to ask in light of the different DCR categories we covered earlier. For the purposes of discussion, we’ll define the two as follows:
Platform – Where the DCR is the central (or one of the central) products within the platform or suite.
Product – Where the DCR is one of many services or features provided by the platform or suite.
The answer of course is both, but it depends on the provider, the collaborators or users, and the use case the DCR is being used to enable. Here’s how I think about it across different categories (Figure U).

Figure U – Platform or Product
Pure Play – It makes sense to think of pure play providers as platforms given they contain native features, partner data and mar/adtech integrations that extend their functionalities to be comparable to that of CDPs.
Media companies – These also fall into the Platform category, but for different reasons. Here, it’s because they are set up for collaborators (usually advertisers) to bring their datasets into the media company’s DCR environment to enable use cases using the company’s media data.
Data companies – In the case of companies like LiveRamp and Acxiom, it makes sense to think of DCRs as products within their large suite of products. That said, their DCR offerings are often powered by other providers. For example, LiveRamp acquired Habu to strengthen its existing DCR offering, while Acxiom’s DCR product is powered by Snowflake.
Walled Gardens – For companies like Google and Amazon, DCRs are clearly products. For example, Ads Data Hub is a product within their larger ads/cloud offering whereas Amazon Ads’ DCR is one of five different features of Amazon Marketing Cloud.
Data Platforms and Managed Clouds – DCRs here can be considered products within a suite of services. As an example, Snowflake’s DCR offering is a feature that can be activated from their larger product set. With AWS, DCRs are just one of many products offered within their cloud infrastructure features and data workloads.
Congratulations, you now know more about Data Clean Rooms than most people in the industry!
If you found this guide useful, check out our other blog posts or subscribe to our YouTube channel for more good stuff.
Last updated: 8 August, 2024

